





Claude Code 最近让一批开发者感觉哪里不对。
用量涨了,但 prompt 没变长。额度跑得更快,但也说不清为什么。直到几位开发者架起 HTTP 代理,把实际传输内容抓包出来,才发现:在 Claude Code v2.1.100 里,每一次 API 请求,背后可能多出了约 20,000 个用户看不见的 Token。
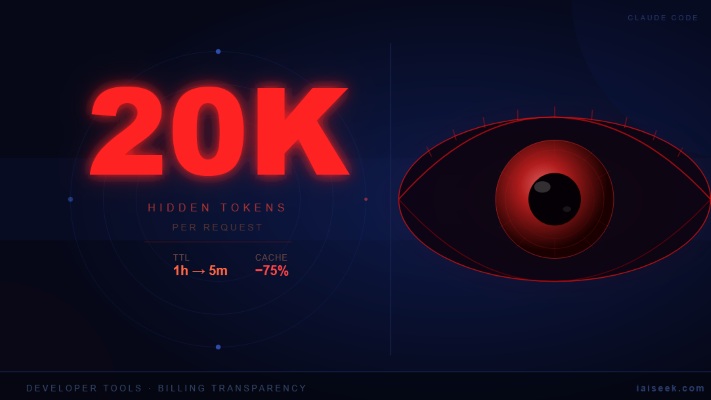
同期还有另一条社区反馈:Anthropic 早在 3 月把 Claude Code 的缓存生存时间(cache TTL)从 1 小时砍到 5 分钟。两件事加在一起,用户实际面对的,可能是一个成本结构被静默重写的工具。
截至发稿,上述说法来自社区侧的抓包分析与开发者讨论,尚无 Anthropic 的完整官方回应。但这正是问题所在。
很多人只看到了显性成本
Claude Code 的定价在台面上是透明的。按模型计费、按 token 收费、订阅制有额度上限——这些都可以查到。
大多数人对"Claude Code 成本"的理解,也就到这里为止:我输入多少,我付多少。
这是一个合理的直觉,但它忽略了一件事:你付的钱,不全是你输入的内容。
隐性成本藏在哪里
Claude Code 作为 AI 编程工具,本来就不是"一问一答"。它在运行时要携带的上下文,包括:代码环境状态、工具调用指令、安全规则、行为约束、Shell 状态、项目结构说明……这些都是系统层自动附加的,不需要你手动输入,也不会显示在你眼前。
这部分内容有多少,用户通常不知道,也很难控制。
如果开发者的抓包结果属实,那在 v2.1.100 里,每次请求自动附加的隐性上下文已经接近 20,000 Token。一个参考点:20,000 Token 大约相当于一篇 15,000 字的中文文章,或一段中等复杂度函数的完整代码加注释。
这些 Token,每次请求都在计费。不管你的 prompt 只是一句"帮我 fix 这个 bug"。
缓存缩短,让隐性成本更难摊薄
如果只是固定附加了一段系统上下文,那在理想情况下,缓存至少能让它在一段时间内不重复计费。
但 cache TTL 从 1 小时缩到 5 分钟,把这条退路堵死了。
开发工作的节奏不是连续的。你会写代码,然后去跑测试、看报错、查文档、切窗口、思考一会儿。稍微中断一下,5 分钟很快就到。缓存失效,上一轮的上下文得重新传,那 20,000 个隐性 Token 重新计一遍。
这种叠加效应很隐蔽,但可以量化:假设一个开发者每天在 Claude Code 上发 30 次请求,每次请求附带 20,000 个隐性 Token,而缓存命中率因为 TTL 缩短而从 70% 降到 20%,那单日实际消耗的 Token 数会是原来的两倍以上,而用户的 prompt 一个字都没多。
显性 vs 隐性成本对比
| 成本类型 | 内容 | 用户可见? | 用户可控? |
|---|---|---|---|
| 用户 prompt | 你实际输入的内容 | ✅ | ✅ |
| 模型回复 | 输出 token | ✅ | 部分 |
| 系统提示 | 平台内置指令 | ❌ | ❌ |
| 隐性上下文(v2.1.100 疑似新增) | 约 20,000 token/次 | ❌ | ❌ |
| 缓存复用节省 | TTL 1h → 5min 后大幅降低 | ❌ | ❌ |
哪类用户最容易被这两件事同时伤到
不是所有人的使用方式都受同等影响。
受影响最大的: 高频使用 Claude Code 做真实开发任务的工程师,尤其是工作节奏偏碎片化(调试-切换-回来)的人。缓存 TTL 短 + 隐性 Token 高,对这类用户是双重打击。
受影响中等的: 用 Claude Code 做较长代码 review 或重构任务的人。单次请求成本更高,但如果任务密集,缓存失效的频率相对低一些。
受影响较小的: 偶尔使用、以一次性问答为主、不太依赖上下文连续性的用户。对他们来说,缓存策略影响不大,隐性 Token 的增量相对也更可接受。
常见问题
Q:隐性 Token 的说法确定吗,Anthropic 有正式说明吗?
目前这一说法来自社区开发者的抓包和代理分析,已有多人复现。Anthropic 尚未就此发布完整官方解释。
Q:cache TTL 缩短有没有官方说明?
据社区反馈,这一调整约发生在 3 月,但没有看到 Anthropic 的正式变更说明或公告。
Q:这对 Claude Code 的实际账单影响多大?
取决于使用频率和工作流。对每天高频使用的开发者,如果两项变化属实,月度实际成本可能明显高于原来的预期。精确数字需要 Anthropic 公开具体策略才能准确估算。
Q:用户有没有办法主动控制这部分成本?
目前在工具层面没有直接调整系统上下文的选项。API 直接调用相对透明,但会失去 Claude Code 的 IDE 集成能力。
最终判断
这次争议的问题不是"系统提示存在"——任何 agent 类工具都有。问题是:规模这么大的隐性 Token,用户完全不可见,而 Anthropic 没有主动说明。
在 AI 编程工具里,计费透明度本来就应该是产品设计的一部分,而不是用户自己去抓包才能发现的事。
贵,开发者可以接受。不透明,才是真正的信任问题。
如果 v2.1.100 的发现被更多人复现,Anthropic 需要正面回答的只有两个问题:这 2 万 Token 是什么,为什么是必要的;TTL 缩短是平台策略,还是会根据用户反馈调整。
这两个问题不答,争议就不会停。